

![]()

In addition to Weibo, there is also WeChat
Please pay attention
![]()
WeChat public account
Shulou




![]()
2026-04-04 Update From: SLTechnology News&Howtos shulou NAV: SLTechnology News&Howtos > Internet Technology >
Share
Shulou(Shulou.com)06/03 Report--
A brief introduction to Spark SQL
Spark SQL is a sub-module of Spark, which is mainly used to manipulate structured data. It has the following characteristics:
Seamlessly mix SQL queries with Spark programs, allowing you to query structured data using SQL or DataFrame API; support multiple development languages; support hundreds of external data sources, including Hive,Avro,Parquet,ORC,JSON and JDBC; support HiveQL syntax as well as Hive SerDes and UDF, allowing you to access existing Hive repositories; support standard JDBC and ODBC connections; support optimizer, column storage and code generation features Support extension and ensure fault tolerance.
2. DataFrame & DataSet2.1 DataFrame
In order to support the processing of structured data, Spark SQL provides a new data structure, DataFrame. DataFrame is a dataset made up of named columns. It is conceptually equivalent to a table in a relational database or data frame in the R/Python language. Because Spark SQL supports development in multiple languages, each language defines the abstraction of DataFrame, mainly as follows:
Language main abstract Scala data [T] & DataFrame (alias of Dataset [Row]) Java data [T] PythonDataFrameRDataFrame2.2 DataFrame vs. RDDs
The main difference between DataFrame and RDDs is that one is for structured data and the other for unstructured data. Their internal data structures are as follows:
There is a clear Scheme structure within DataFrame, that is, column names and column field types are known, which has the advantage of reducing data reading and better optimizing the execution plan, thus ensuring query efficiency.
How should DataFrame and RDDs be chosen?
If you want to use functional programming instead of DataFrame API, use RDDs; if your data is unstructured (such as streaming or character streaming), use RDDs, and if your data is structured (such as data in RDBMS) or semi-structured (such as logs), DataFrame should be preferred for performance reasons. 2.3 DataSet
Dataset is also a distributed data collection, which was introduced in Spark version 1.6. it integrates the advantages of RDD and DataFrame, has the characteristics of strong typing, and supports Lambda functions, but it can only be used in Scala and Java languages. After Spark 2.0, for the convenience of developers, Spark combines the API of DataFrame and Dataset to provide a structured API (Structured API), that is, users can operate on both through a set of standard API.
Note here: DataFrame is marked as Untyped API and DataSet is marked as Typed API, both of which will be explained later.
2.4 static types and runtime type safety
Static types (Static-typing) and runtime type safety (runtime type-safety) are mainly shown as follows:
In practice, if you use Spark SQL queries, you won't find syntax errors until run time, while if you use DataFrame and Dataset, you can find errors at compile time (which saves development time and overall cost). The main differences between DataFrame and Dataset are:
In DataFrame, when you call a function other than API, the compiler reports an error, but if you use a field name that does not exist, the compiler still cannot find it. Dataset's API is represented by Lambda functions and JVM type objects, and all mismatched type parameters are found at compile time.
All of the above is ultimately interpreted as a type safety graph, corresponding to syntax and parsing errors in development. In the graph, Dataset is the strictest, but it is the most efficient for developers.
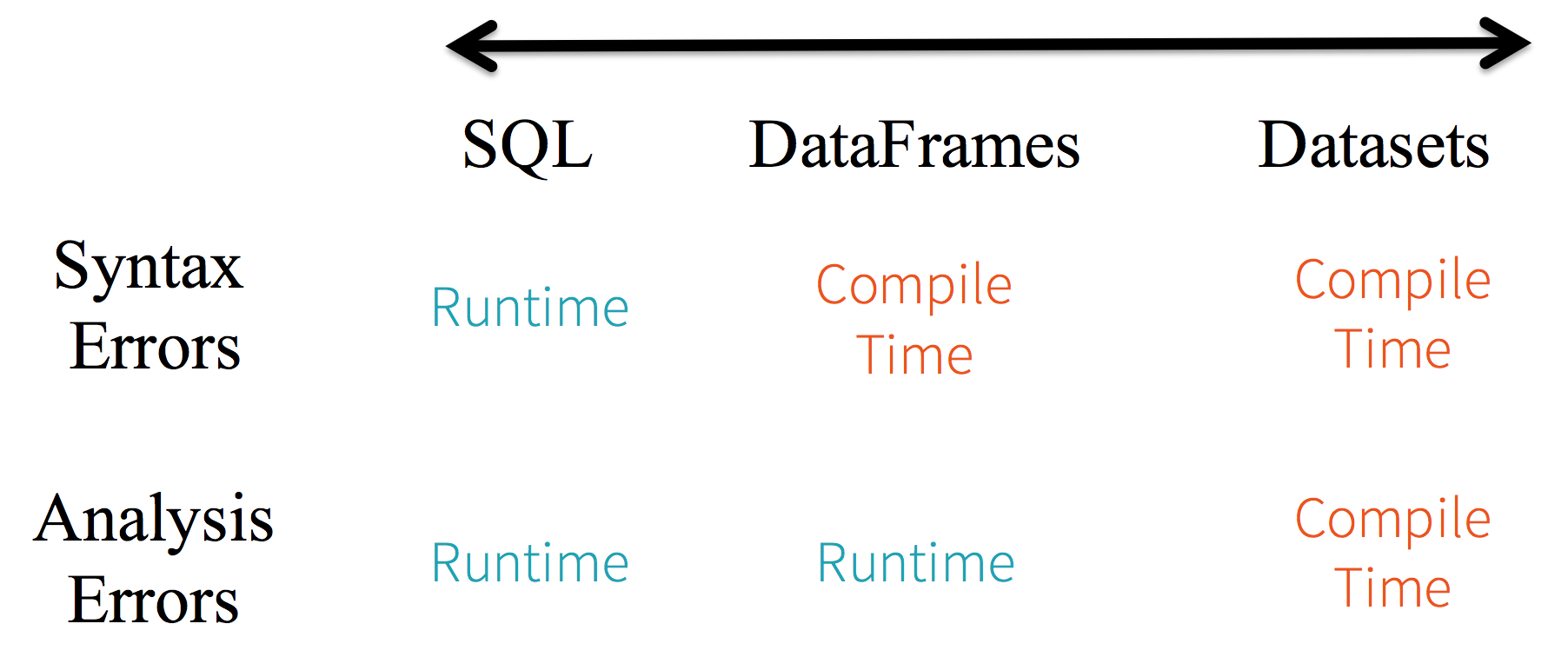
The above description may not be so intuitive, and the following is an example of code compilation in IDEA:
One possible doubt here is that DataFrame obviously has a definite Scheme structure (that is, column names and column field types are all known), but why it is still impossible to infer and misjudge column names, this is because DataFrame is Untyped.
2.5 Untyped & Typed
We mentioned above that DataFrame API is marked as Untyped API and DataSet API is marked as Typed API. DataFrame's Untyped is relative to the language or API level, it does have a clear Scheme structure, that is, column names, column types are determined, but this information is maintained entirely by Spark, and Spark only checks whether these types are consistent with the specified types at run time. This is why, after Spark 2.0, it is officially recommended that DataFrame be thought of as DatSet [Row], and Row is a trait defined in Spark, whose subclasses encapsulate column field information.
Relatively speaking, DataSet is Typed, that is, strong type. As in the following code, the type of DataSet is clearly specified by Case Class (Scala) or Java Bean (Java), where each row of data represents a Person, and this information is guaranteed by JVM, so field name errors and type errors will be found by IDE at compile time.
Case class Person (name: String, age: Long) val dataSet: Dataset [Person] = spark.read.json ("people.json"). As [person] III. DataFrame & DataSet & RDDs summary
Here is a brief summary of the three:
RDDs is suitable for unstructured data processing, while DataFrame & DataSet is more suitable for structured data and semi-structured data processing; DataFrame & DataSet can be accessed through a unified Structured API, while RDDs is more suitable for functional programming scenarios; compared with DataFrame, DataSet is strongly typed (Typed) and has more stringent static type checking; the underlying layers of DataSets, DataFrames and SQL all rely on RDDs API and provide structured access interfaces.
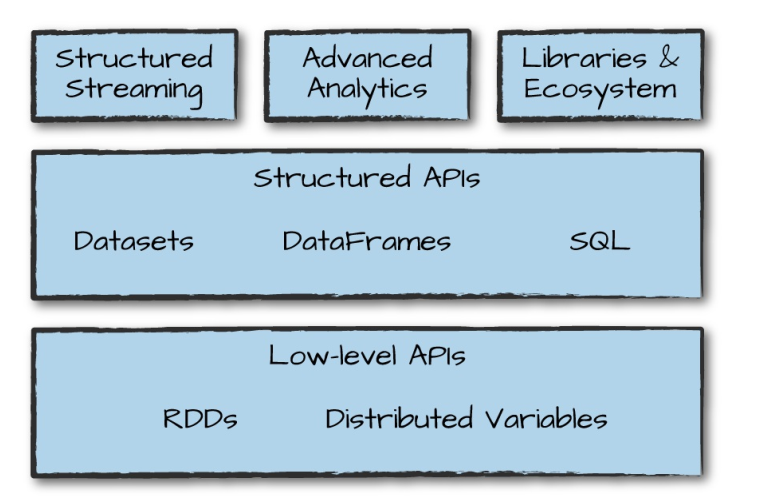
Fourth, the operation principle of Spark SQL
The actual execution processes of DataFrame, DataSet, and Spark SQL are all the same:
Do DataFrame/Dataset/SQL programming; if the code is valid, that is, the code has no compilation errors, Spark converts it into a logical plan; Spark converts this logical plan into a physical plan and optimizes the code; Spark then executes the physical plan on the cluster (based on RDD operations). 4.1 logical Plan (Logical Plan)
The first phase of execution is to convert the user code into a logical plan. It first converts user code to unresolved logical plan (unresolved logical plan), which is unresolved because although your code is syntactically correct, the tables or columns it references may not exist. Spark uses analyzer (parser) to parse based on catalog (all stored table and DataFrames information). If the parsing fails, it refuses to execute, and if the parsing succeeds, the result is passed to the Catalyst optimizer (Catalyst Optimizer). The optimizer is a set of rules that are used to optimize the logical plan, optimize it by pushing down predicates, and finally output the optimized logical execution plan.
4.2 physical Program (Physical Plan)
With the optimized logical plan, Spark begins the physical planning process. It selects an optimal physical plan to execute on the cluster by generating different physical execution strategies and comparing them through cost models. The output of physical planning is a series of RDDs and transformation relationships (transformations).

4.3 execution
After selecting a physical plan, Spark runs its RDDs code, performs further optimizations at run time, generates local Java bytecode, and finally returns the run result to the user.
Reference materials Matei Zaharia, Bill Chambers. Spark: The Definitive Guide [M]. 2018-02Spark SQL, DataFrames and Datasets Guide and talk about Apache Spark's API three Musketeers: RDD, DataFrame and Dataset A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets (original)
For more articles in big data's series, please see the GitHub Open Source Project: big data's getting started Guide.
Welcome to subscribe "Shulou Technology Information " to get latest news, interesting things and hot topics in the IT industry, and controls the hottest and latest Internet news, technology news and IT industry trends.
Views: 0
*The comments in the above article only represent the author's personal views and do not represent the views and positions of this website. If you have more insights, please feel free to contribute and share.

The market share of Chrome browser on the desktop has exceeded 70%, and users are complaining about

The world's first 2nm mobile chip: Samsung Exynos 2600 is ready for mass production.According to a r


A US federal judge has ruled that Google can keep its Chrome browser, but it will be prohibited from

Continue with the installation of the previous hadoop.First, install zookooper1. Decompress zookoope



About us Contact us Product review car news thenatureplanet
More Form oMedia: AutoTimes. Bestcoffee. SL News. Jarebook. Coffee Hunters. Sundaily. Modezone. NNB. Coffee. Game News. FrontStreet. GGAMEN
© 2024 shulou.com SLNews company. All rights reserved.
 12
12
 Report
Report







