

![]()

In addition to Weibo, there is also WeChat
Please pay attention
![]()
WeChat public account
Shulou




![]()
2026-03-16 Update From: SLTechnology News&Howtos shulou NAV: SLTechnology News&Howtos > Servers >
Share
Shulou(Shulou.com)05/31 Report--
This article focuses on "what are the Spark Streaming programming skills", interested friends may wish to have a look. The method introduced in this paper is simple, fast and practical. Let's let the editor take you to learn what Spark Streaming programming skills are.
# Spark Streaming programming Guide #
# # Overview # # Spark Streaming is an extension of the core Spark API, which can achieve high throughput and fault-tolerant real-time data stream processing.
He can accept data from many data sources such as Kafka, Flume, Twitter, ZeroMQ, or plain old TCP sockets. Data can be processed using complex algorithmic expressions with high-level functions such as map, reduce, join, and window. Eventually, the processed data can be pushed to the file system, database, and online dashboards. In fact, you can apply Spark's built-in machine learning algorithm and graph processing algorithm to the data stream.

Internally, it works as follows. Spark Streaming receives the real-time input data stream and splits the data into batches,which are then processed by the Spark engine to generate the final stream of results in batches.
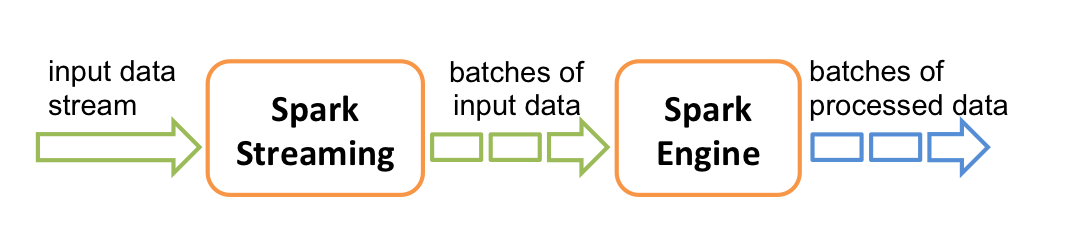
Spark Streaming provides a high-level abstraction called discrete flow, or DStream. It represents a continuous data stream. DStreams can be created either from data streams from data sources such as Kafka or Flume, or by applying advanced operations to other DStreams. Internally, a DStream is represented as a sequence of RDDs.
This guide shows you how to start writing Spark Streaming programs using DStreams. You can write Spark Streaming programs in Scala or Java, both of which are provided in this guide. You will find that tabs runs through the full text, allowing you to choose between Scala and Java code snippets.
# # A simple example # # before we get into the details of how to write your own Spark Streaming program, let's take a quick look at what the next simple Spark Streaming program looks like. For example, we want to calculate the total number of words in the text data on a data server obtained by listening for TCP sockets. All you need to do is as follows:
First, we create a JavaStreamingContext object, which is a pointcut for all Streaming functions. In addition to the Spark configuration, we specify that any DStream would be processed in 1 second batches.
Import org.apache.spark.api.java.function.*;import org.apache.spark.streaming.*;import org.apache.spark.streaming.api.java.*;import scala.Tuple2;// Create aStreamingContext with a local masterJavaStreamingContext jssc = new JavaStreamingContext ("local [2]", "JavaNetworkWordCount", new Duration (1000))
Using this context, we create a new DStream by specifying the IP address and the port of the data server.
/ / Create a DStream that will connect to serverIP:serverPort, like localhost:9999JavaReceiverInputDStream lines = jssc.socketTextStream ("localhost", 9999)
This DStream lines indicates that the stream of data will be received from this data server. Each record in the stream is a line of text. Then we divide the lines into words by spaces.
/ / Split each line into wordsJavaDStream words = lines.flatMap (new FlatMapFunction () {@ Override public Iterable call (String x) {return Arrays.asList (x.split ("));}})
FlatMap is a DStream operation that creates a new DStream by causing each record in the source DStream to generate many new records. In this example, each line will be split into multiple words,words streams and represented as words DStream. Note that we define using FlatMapFunction object transformations. As we have been exploring, there are many such transformation classes in Java API to help define DStream transformations.
For the next two, we want to calculate the sum of these words:
/ / Count each word in each batchJavaPairDStream pairs = words.map (new PairFunction () {@ Override public Tuple2 call (String s) throws Exception {return new Tuple2 (s, 1);}}); JavaPairDStream wordCounts = pairs.reduceByKey (new Function2 () {@ Override public Integer call (Integer i1, Integer i2) throws Exception {return i1 + i2;}}); wordCounts.print (); / / Print a few of the counts to the console
Using a PairFunction,words DStream is further mapped (one-to-one conversion) into a DStream pair (word,1). Then, use the Function2 object, it is reduced to get the frequency of words in each batch of data. Finally, wordCounts.print () will print some generated sums every second.
Note that when these lines are executed, Spark Streaming only sets up the computation it will perform when it is started, and no real processing has started yet. To start the processing after all the transformations have been setup, we finally call
Jssc.start (); / / Start the computationjssc.awaitTermination (); / / Wait for the computation to terminate
The complete code can be found at Spark Streaming example JavaNetworkWordCount.
If you have downloaded and built Spark, you can run this example like this. You need to first run Netcat (a gadget that can be found on most Unix-like systems) as a data server by:
$nc-lk 9999
Then, under a different terminal, you can also start this example by:
$. / bin/run-example org.apache.spark.examples.streaming.JavaNetworkWordCount localhost 9999
Then, each line entered in the terminal running the netcat service will be summed and printed on the screen every second. He looks like this:
# TERMINAL 1: # Running Netcat $nc-lk 9999 hello world... # TERMINAL 2: RUNNING NetworkWordCount or JavaNetworkWordCount $. / bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999...-Time: 1357008430000 ms- -(hello 1) (world,1)...
You can also use Spark Streaming directly from Spark shell:
$bin/spark-shell
... And create your StreamingContext by encapsulating the existing interactive shell SparkContext object sc:
Val ssc = new StreamingContext (sc, Seconds (1))
When working with the shell, you may also need to send a ^ D to your netcat session to force the pipeline to print the word counts to the console at the sink.
# # Basics # # now, move beyond the simple example, let's elaborate on the basics of Spark Streaming that you need to know to write a streaming application.
# access # # to write your own Spark Streaming program, you will need to add the following dependencies to your SBT or Maven project:
GroupId = org.apache.sparkartifactId = spark-streaming_2.10version = 1.0.2
The ability to fetch data from data sources such as Kafka and Flume is now available in Spark Streaming's core API. You will need to add the corresponding attiface spark-streaming-xyz_2.10 to the dependency. For example, here are some common ones:
Source Artifact Kafka spark-streaming-kafka_2.10 Flume spark-streaming-flume_2.10 Twitter spark-streaming-twitter_2.10 ZeroMQ spark-streaming-zeromq_2.10 MQTT spark-streaming-mqtt_2.10
For a list of crimes, refer to Apache repository's list of all supported sources and artifacts.
# initialize # # in Java, to initialize a Spark Streaming program, you need to create a JavaStreamingContext object, which is the entry point for the entire Spark Streaming function. A JavaStreamingContext object can be created, using:
New JavaStreamingContext (master, appName, batchInterval, [sparkHome], [jars])
The master parameter is a standard Spark cluster URL, and can be "local" as a local test. AppName is the name of your program, which will be displayed in the Web UI of your cluster. BatchInterval is the size of batches, as explained earlier. Finally, if you are running in distributed mode, you need the last two parameters to deploy your code to a cluster, as described by Spark programming guide. In addition, basic SparkContext can be accessed like ssc.sparkContext.
Batch internal must be set according to the latency requirements of your application and the available cluster resources. Check Performance Tuning for more details.
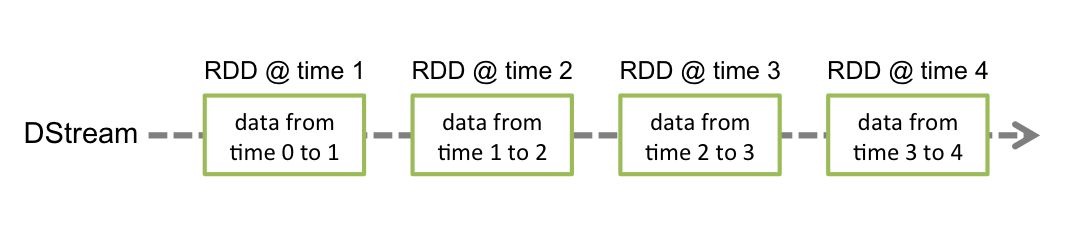
# DStreams### Discretized Stream or DStream is the basic abstraction provided by Spark Streaming. It represents a continuous data stream, either an input data stream from a data source, or a processed data stream generated by transforming an input stream. Internally, it is represented by a continuous sequence of RDDs, which is an immutable, distributed data machine of Spark. Each RDD in a DStream contains data from a certain interval, as shown in the following chart:
Any operation applied to a DStream translates into an operation on the underlying RDDs. For example, in the earlier example of converting a stream of lines to words, the flatmap operation is applied on each RDD in the lines DStream to generate the RDDs of the words DStream. The following chart shows this:
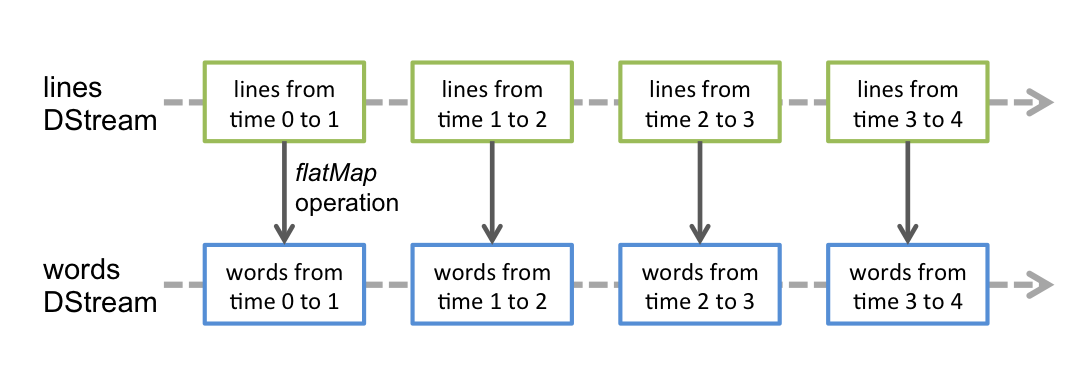
These basic RDD transformations are calculated by the Spark engine. The DStream operation hides most of the details and provides a high-level API for developers' convenience. These operations are discussed in detail in later chapters.
# input source # # We have seen ssc.socketTextStream (...) in [quick example] (quick example), which creates a DStream by accepting text data through a TCP socket connection. In addition to sockets, the core Spark Streaming API provides the creation of DStream through files and the use of Akka actors as the input source.
In particular, for files, DStream can be created as follows:
Jssc.fileStream (dataDirectory)
Spark Streaming will monitor any Hadoop-compatible file systems in the dataDirectory directory and process any files created in that directory.
Note:
Documents must have a uniform format
The files must be created in the dataDirectory by atomically moving or renaming them into the data directory.
Once moved the files must not be changed.
For more details on streams from files, Akka actors and sockets, see the API documentations of the relevant functions in StreamingContext for Scala and JavaStreamingContext for Java.
In addition, the ability to create DStream through sources such as Kafka, Flume, and Twitter can be imported and the correct dependencies added, as explained in the previous section. In the case of Kafka, after adding artifact spark-streaming-kafka_2.10 to the project's dependencies, you can create a DStream from Kafka like this:
Import org.apache.spark.streaming.kafka.*;KafkaUtils.createStream (jssc, kafkaParams,...)
For more details about additional sources, check the corresponding API documentation. In addition, you can implement your own custom recipients of sources and check out Custom Receiver Guide.
# Operation # # there are two DStream operations-conversion and output. Similar to the RDD transformation, the DStream transformation operation creates a new DStreams containing the transformation data for one or more DStream. After applying a series of transformations to the data stream, the input operation needs to be called, which writes the data to an additional data slot, such as a file system or a database.
# conversion # DStream supports many transformations on a normal Spark RDD. Here are some common transformations:
Transformation Meaning map (func) Return a new DStream by passing each element of the source DStream through a function func. FlatMap (func) Similar to map, but each input item can be mapped to 0 or more output items. Filter (func) Return a new DStream by selecting only the records of the source DStream on which func returns true. Repartition (numPartitions) Changes the level of parallelism in this DStream by creating more or fewer partitions. Union (otherStream) Return a new DStream that contains the union of the elements in the source DStream and otherDStream. Count () Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. Reduce (func) Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative so that it can be computed in parallel. CountByValue () When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. ReduceByKey (func, [numTasks]) When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. Join (otherStream, [numTasks]) When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. Cogroup (otherStream, [numTasks]) When called on DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq [V], Seq [W]) tuples. Transform (func) Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. UpdateStateByKey (func) Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key.
The last two transformations are worth explaining again.
# UpdateStateByKey operation # updateStateByKey allows you to maintain any state and update new information continuously. To use it, you need the following two steps:
Define state-state can be any data type
Define a state update function-specify a function to update the state from the previous state and the values of the new input stream
Let's use an example to illustrate. Suppose we want to maintain the number of occurrences of words in a continuous text stream. Here, the continuous sum is this state, and it is an Integer, and we define the update function, like this:
Import com.google.common.base.Optional;Function2 updateFunction = new Function2 () {@ Override public Optional call (List values, Optional state) {Integer newSum =... / / add the new values with the previous running count to get the new count return Optional.of (newSum);}}
The following application is applied to a DStream that contains words (assuming that Pairs DStream contains (word, 1) pairs in quick example)
The update function will be called by every word, with newValues having a sequence of 1s (from the (word, 1) pairs) and the runningCount having the previous count. For the complete Scala code, check out the example StatefulNetworkWordCount.
# Transform operation #
# Window operation # finally, Spark Streaming also provides window calculation.
# Output operation # when an output operation is called, it starts a stream calculation. Currently, the following output operation is defined:
Output Operation Meaning print () Prints first ten elements of every batch of data in a DStream on the driver. ForeachRDD (func) The fundamental output operator. Applies a function, func, to each RDD generated from the stream. This function should have side effects, such as printing output, saving the RDD to external files, or writing it over the network to an external system. SaveAsObjectFiles (prefix, [suffix]) Save this DStream's contents as a SequenceFile of serialized objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS [.suffix]". SaveAsTextFiles (prefix, [suffix]) Save this DStream's contents as a text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS [.suffix]". SaveAsHadoopFiles (prefix, [suffix]) Save this DStream's contents as a Hadoop file. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS [.suffix]".
A complete list of DStream operations can be found in the API document. For Scala API, look at DStream and PairDStreamFunctions, and for Java API, see JavaDStream and JavaPairDStream.
# persistence # # similar to RDDs,DStreams, developers are also allowed to persist stream data to memory. That is, using persist () on a DStream will automatically persist every RDD of the DStream to memory. This is useful if the data in this DStream will be calculated multiple times (for example, performing multiple operations on the same data). Window-based operations such as reduceByWondow and reduceByKeyAndWindow and state-based operations such as updateStateByKey are persisted by default. Therefore, the DStream generated through window-based operations is automatically persisted to memory without requiring the developer to call the persist () method.
For a data stream, it receives data through network (such as Kafka,Flume,socket, etc.), and its default persistence level is to copy data to two nodes for fault tolerance.
Note that the default persistence level for RDDs,DSteam is to keep the data serialized in memory. There is more discussion in the chapter Performance Tuning. More information about the different persistence levels can be found at Spark Programming Guide.
# RDD Checkpointing### one stateful operation is one of those operations on multiple batches of data. It includes all window-based operations and updateStateByKey operations. Because stateful operations rely on the batches of previous data, they continuously aggregate metadata over time. To clear this data, Spark Streaming supports periodic checkpointing when storing intermediate data to HDFS.
To enable checkpointing, the developer needs to provide the HDFS path where the RDD will be saved. This is done with the following code:
Ssc.checkpoint (hdfsPath) / / assuming ssc is the StreamingContext or JavaStreamingContext
The interval between the checkpointing of a DStream can be set as follows:
Dstream.checkpoint (checkpointInterval)
For DStream, it must be checkpointing (that is, DStream is created by updateStateByKey and uses the opposite function reduceByKeyAndWindow), and the checkpoint interval for DStream is set to set to a multiple of the DStream's sliding interval by default, for example, at least 10 seconds.
# Deployment###, like any other Spark application, the Spark Streaming application is deployed on the cluster. Please refer to deployment guide for more information.
If a running Spark Streaming application needs to be upgraded (including new application code), here are two possible tips:
The upgraded Spark Streaming application is started and run in parallel to the existing application. Once the new one (receiving the same data as the old one) has been warmed up and ready for prime time, the old one be can be brought down. Note that this can be done for data sources that support sending the data to two destinations (i.e., the earlier and upgraded applications).
The existing application is shutdown gracefully (see StreamingContext.stop (...) Or JavaStreamingContext.stop (...) For graceful shutdown options) which ensure data that have been received is completely processed before shutdown. Then the upgraded application can be started, which will start processing from the same point where the earlier application left off. Note that this can be done only with input sources that support source-side buffering (like Kafka, and Flume) as data needs to be buffered while the previous application down and the upgraded application is not yet up.
At this point, I believe you have a deeper understanding of "what are Spark Streaming programming skills?" you might as well do it in practice. Here is the website, more related content can enter the relevant channels to inquire, follow us, continue to learn!
Welcome to subscribe "Shulou Technology Information " to get latest news, interesting things and hot topics in the IT industry, and controls the hottest and latest Internet news, technology news and IT industry trends.
Views: 0
*The comments in the above article only represent the author's personal views and do not represent the views and positions of this website. If you have more insights, please feel free to contribute and share.

The market share of Chrome browser on the desktop has exceeded 70%, and users are complaining about

The world's first 2nm mobile chip: Samsung Exynos 2600 is ready for mass production.According to a r


A US federal judge has ruled that Google can keep its Chrome browser, but it will be prohibited from

Continue with the installation of the previous hadoop.First, install zookooper1. Decompress zookoope



About us Contact us Product review car news thenatureplanet
More Form oMedia: AutoTimes. Bestcoffee. SL News. Jarebook. Coffee Hunters. Sundaily. Modezone. NNB. Coffee. Game News. FrontStreet. GGAMEN
© 2024 shulou.com SLNews company. All rights reserved.
 12
12
 Report
Report







