

![]()

In addition to Weibo, there is also WeChat
Please pay attention
![]()
WeChat public account
Shulou




![]()
2026-03-20 Update From: SLTechnology News&Howtos shulou NAV: SLTechnology News&Howtos > Internet Technology >
Share
Shulou(Shulou.com)06/03 Report--
Introduction to Hadoop Yarn
Apache YARN (Yet Another Resource Negotiator) is a cluster resource management system introduced by Hadoop 2.0. Users can deploy various service frameworks on YARN, and YARN can manage and allocate resources uniformly.
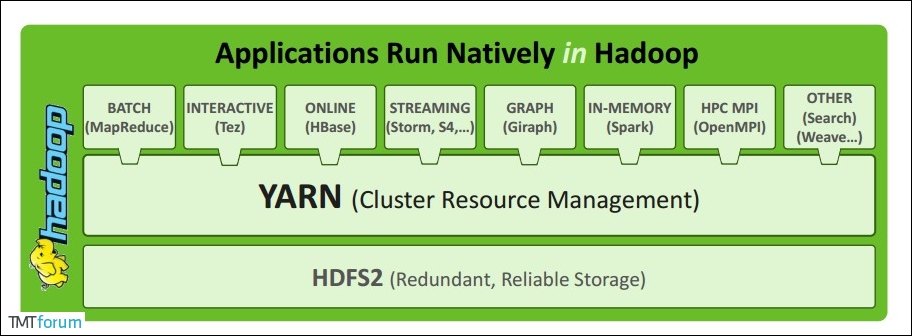
II. YARN Architecture
1. ResourceManager
ResourceManager, which typically runs as a background process on a separate machine, is the primary coordinator and manager of the entire cluster's resources. ResourceManager is responsible for allocating resources to all applications submitted by users. It makes decisions based on information such as application priority, queue size, ACLs, data location, etc., and then formulates allocation policies in a shared, secure, multi-tenant manner to schedule cluster resources.
2. NodeManager
The NodeManager is the manager of each specific node in the YARN cluster. It is mainly responsible for the lifecycle management of all containers in the node, monitoring resources and tracking node health. The details are as follows:
Register with ResourceManager and send heartbeat messages regularly when starting, wait for instructions from ResourceManager; maintain the lifecycle of Container, monitor resource usage of Container; manage related dependencies when task runs, copy required programs and their dependencies to local before starting Container according to the needs of ApplicationMaster. 3. ApplicationMaster
When a user submits an application, YARN starts a lightweight process called ApplicationMaster. The ApplicationMaster coordinates resources from the ResourceManager and monitors resource usage within the container through the NodeManager, as well as task monitoring and fault tolerance. The details are as follows:
Determine dynamic computing resource requirements according to application running status; apply for resources from ResourceManager, monitor the usage of applied resources; track task status and progress, report resource usage and application progress information; be responsible for fault tolerance of tasks. 4. Contain
Container is a resource abstraction in YARN, which encapsulates multidimensional resources on a node, such as memory, CPU, disk, network, etc. When AM requests resources from RM, RM returns resources for AM represented by Container. YARN assigns a Container to each task, which can only use the resources described in that Container. ApplicationMaster can run any type of task inside a Container. For example, MapReduce ApplicationMaster requests a container to start map or reduce tasks, while Giraffe ApplicationMaster requests a container to run Giraffe tasks.
III. Brief description of YARN working principle
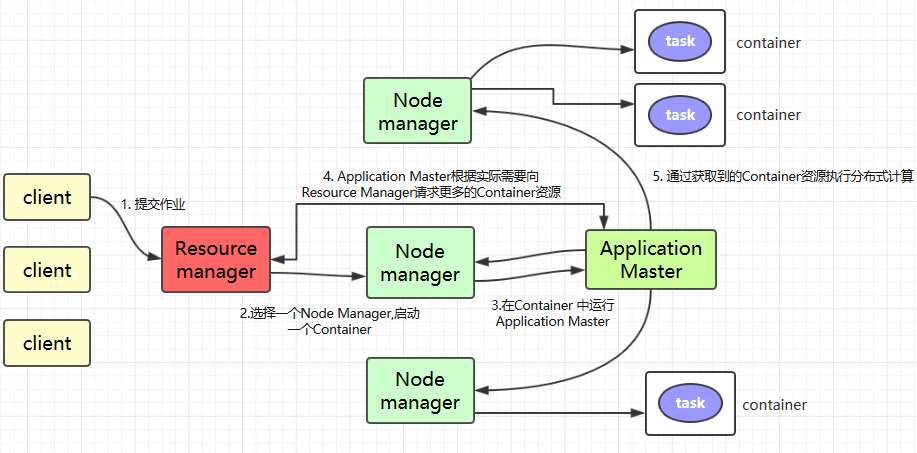
Client submits jobs to YARN;
Resource Manager Select a Node Manager, start a Container and run the Application Master instance;
Application Master requests more Container resources from Resource Manager as needed (if the job is small, Application Manager chooses to run the task in its own JVM);
The Application Master performs distributed computation with the acquired Container resources. IV. Detailed working principle of YARN
1. job submission
The client calls the job.waitForCompletion method to submit MapReduce jobs to the entire cluster (step 1). A new job ID(application ID) is assigned by the resource manager (step 2). The client of the job verifies the output of the job, calculates the split of the input, and copies the resources of the job (including Jar package, configuration file, split information) to HDFS(step 3). Finally, submit the job by calling submitApplication() of the Resource Manager (step 4).
2. job initialization
When the resource manager receives a request for submitApplication (), it sends the request to the scheduler, which assigns the container, and then the resource manager starts the application manager process in the container, which is monitored by the node manager (step 5).
The MapReduce job application manager is a Java application whose main class is MRAppMaster, which monitors the progress of the job by creating some bookkeeping objects and gets progress and completion reports of the task (step 6). It then gets the input splits computed by the client through the distributed file system (step 7), and then creates a map task for each input split, creating a reduce task object from mapreduce.job.reduces.
3. task allocation
If the job is small, the app manager chooses to run the task in its own JVM.
If it is not a small job, the application manager requests the container from the resource manager to run all map and reduce tasks (step 8). These requests are transmitted by heartbeat and include the data location of each map task, such as the hostname and rack where the input split is stored, and the scheduler uses this information to schedule tasks and try to assign tasks to nodes that store data or to nodes in the same rack as the node where the input split is stored.
4. task runs
When a task is assigned to a container by the scheduler of the resource manager, the application manager starts the container by contacting the node manager (step 9). The task is executed by a Java application whose main class is YarnChild. Before running the task, first localize the resources required by the task, such as job configuration, JAR files, and all files in the distributed cache (Step 10). Finally, run the map or reduce task (Step 11).
YarnChild runs in a dedicated JVM, but YARN does not support JVM reuse.
5. Progress and status updates
Tasks in YARN return their progress and status (including counters) to the application manager, and clients request progress updates from the application manager every second (via mareduce.client.progressmonitor.pollinterval settings), which are displayed to users.
6. job completes
In addition to requesting job progress from the application manager, clients check job completion every 5 minutes by calling waitForCompletion() at intervals that can be set via mapreduce.client.completion.pollinterval. After the job completes, the application manager and container clean up the work state, and the OutputCommit job cleanup method is called. Job information is stored by the job history server for later review by users.
5. Submit the job to run on YARN
Here, take the MApReduce program that calculates Pi in Hadoop Examples as an example. The relevant Jar package is in the share/hadoop/mapreduce directory of the Hadoop installation directory:
#Submission format: hadoop jar package path main class name main class parameters # hadoop jar hadoop-mapreduce-examples-2.6.0-cdh6.15.2.jar pi 3 3 References
A preliminary grasp of Yarn's architecture and principles
Apache Hadoop 2.9.2 > Apache Hadoop YARN
More articles on Big Data can be found at GitHub Open Source Project: Big Data Getting Started Guide.
Welcome to subscribe "Shulou Technology Information " to get latest news, interesting things and hot topics in the IT industry, and controls the hottest and latest Internet news, technology news and IT industry trends.
Views: 0
*The comments in the above article only represent the author's personal views and do not represent the views and positions of this website. If you have more insights, please feel free to contribute and share.

The market share of Chrome browser on the desktop has exceeded 70%, and users are complaining about

The world's first 2nm mobile chip: Samsung Exynos 2600 is ready for mass production.According to a r


A US federal judge has ruled that Google can keep its Chrome browser, but it will be prohibited from

Continue with the installation of the previous hadoop.First, install zookooper1. Decompress zookoope



About us Contact us Product review car news thenatureplanet
More Form oMedia: AutoTimes. Bestcoffee. SL News. Jarebook. Coffee Hunters. Sundaily. Modezone. NNB. Coffee. Game News. FrontStreet. GGAMEN
© 2024 shulou.com SLNews company. All rights reserved.
 12
12
 Report
Report







