

![]()

In addition to Weibo, there is also WeChat
Please pay attention
![]()
WeChat public account
Shulou




![]()
2026-04-08 Update From: SLTechnology News&Howtos shulou NAV: SLTechnology News&Howtos > Internet Technology >
Share
Shulou(Shulou.com)06/03 Report--
I. introduction
HDFS (Hadoop Distributed File System) is a distributed file system under Hadoop, which has the characteristics of high fault tolerance and high throughput, and can be deployed on low-cost hardware.
II. Design principle of HDFS
2.1 HDFS architecture
HDFS follows the master / slave architecture and consists of a single NameNode (NN) and multiple DataNode (DN):
NameNode: responsible for performing operations on file system namespaces, such as opening, closing, renaming files and directories, etc. It is also responsible for the storage of cluster metadata, recording the location information of each data block in the file. DataNode: responsible for providing read and write requests from the file system client, performing block creation, deletion and other operations. 2.2 File system Namespace
HDFS's file system namespace has a hierarchical structure similar to that of most file systems (such as Linux), supporting the creation, movement, deletion, and renaming of directories and files, and the configuration of users and access rights, but not hard and soft links. NameNode is responsible for maintaining file system namespaces and recording any changes to namespaces or their attributes.
2.3 data replication
Because Hadoop is designed to run on cheap machines, which means that the hardware is unreliable, HDFS provides a data replication mechanism to ensure fault tolerance. HDFS stores each file as a series of blocks, each with multiple copies to ensure fault tolerance, and the block size and replication factor can be configured on its own (by default, the block size is 128m, and the default replication factor is 3).
2.4 the implementation principle of data replication
Large HDFS instances are located on multiple servers that are usually distributed in multiple racks, and two servers on different racks communicate through switches. In most cases, the network bandwidth between servers in the same rack is greater than that between servers in different racks. Therefore, HDFS adopts a rack-aware replica placement strategy, and for common cases, when the replication factor is 3, the placement policy for HDFS is:
When the writer is on the datanode, a copy of the write file is placed first on the datanode, otherwise on the random datanode. Then place another copy on any node on another remote rack and the last copy on another node on that rack. This strategy improves write performance by reducing write traffic between racks.
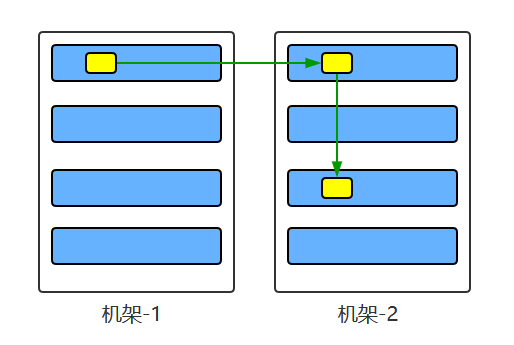
If the replication factor is greater than 3, randomly determine the placement of the 4th and later replicas while keeping the number of replicas per rack below the upper limit, usually (replication factor-1) / number of racks + 2, it is important to note that multiple replicas of the same block on the same dataNode are not allowed.
2.5 selection of copies
To minimize bandwidth consumption and read latency, HDFS gives priority to reading the copy closest to the reader when performing a read request. If there is a copy on the same rack as the reader node, the copy is preferred. If the HDFS cluster spans multiple data centers, the replica on the local data center takes precedence.
2.6 Stability of the architecture 1. Heartbeat mechanism and re-replication
Each DataNode sends a heartbeat message to the NameNode periodically, and if the heartbeat message is not received after the specified time, the DataNode is marked as dead. NameNode will not forward any new IO requests to the DataNode marked as dead, nor will it use the data on these DataNode. Because the data is no longer available, it may cause the replication factor of some blocks to be less than their specified value, and NameNode tracks these blocks and replicates them again if necessary.
two。 Integrity of data
Data blocks stored on DataNode can also be damaged due to storage device failure and other reasons. In order to avoid errors caused by reading corrupted data, HDFS provides a data integrity verification mechanism to ensure the integrity of the data, as follows:
When the client creates a HDFS file, it calculates the checksum for each block of the file and stores the checksum in a separate hidden file under the same HDFS namespace. When the client retrieves the contents of the file, it verifies that the data received from each DataNode matches the checksum stored in the associated checksum file. If the match fails, the data is proved to be corrupted, and the client chooses to obtain another available copy of the block from another DataNode.
3. Disk failure of metadata
FsImage and EditLog are the core data of HDFS, and the accidental loss of these data may make the entire HDFS service unavailable. To avoid this problem, NameNode can be configured to support FsImage and EditLog multi-replica synchronization, so that any changes to FsImage or EditLog will cause synchronous updates of FsImage and EditLog for each copy.
4. Support for snapshots
Snapshots support the storage of copies of data at a specific time, and can be restored to a healthy data state through a rollback operation if the data is accidentally damaged.
Third, the characteristics of HDFS 3.1 high fault tolerance
Because HDFS adopts the multi-copy scheme of data, the damage of part of the hardware will not lead to the loss of all data.
3.2 High throughput
HDFS design focuses on supporting high-throughput data access rather than low-latency data access.
3.3 large file support
HDFS is suitable for storing large files, and the size of the document should be from GB to TB.
3.3 simple consistency model
HDFS is more suitable for the access model of write-once read-multiple (write-once-read-many). Appending content to the end of the file is supported, but random access to data is not supported, and data cannot be added from anywhere in the file.
3.4 Cross-platform portability
HDFS has a good cross-platform portability, which makes other big data computing frameworks regard it as the preferred solution for persistent data storage.
Attached: illustrating the principle of HDFS storage
Note: the following pictures are quoted from the blog: translation of classic HDFS principles to explain comics
1. The principle of HDFS writing data
2. The principle of HDFS reading data
3. HDFS fault types and their detection methods
Part two: the handling of read and write faults.
Part III: fault handling of DataNode
Copy layout strategy:
Reference material Apache Hadoop 2.9.2 > HDFS ArchitectureTom White. Authoritative Guide to hadoop [M]. Tsinghua University Press. 2017. Translation of classic HDFS principles to explain comics
For more articles in big data's series, please see the GitHub Open Source Project: big data's getting started Guide.
Welcome to subscribe "Shulou Technology Information " to get latest news, interesting things and hot topics in the IT industry, and controls the hottest and latest Internet news, technology news and IT industry trends.
Views: 0
*The comments in the above article only represent the author's personal views and do not represent the views and positions of this website. If you have more insights, please feel free to contribute and share.

The market share of Chrome browser on the desktop has exceeded 70%, and users are complaining about

The world's first 2nm mobile chip: Samsung Exynos 2600 is ready for mass production.According to a r


A US federal judge has ruled that Google can keep its Chrome browser, but it will be prohibited from

Continue with the installation of the previous hadoop.First, install zookooper1. Decompress zookoope



About us Contact us Product review car news thenatureplanet
More Form oMedia: AutoTimes. Bestcoffee. SL News. Jarebook. Coffee Hunters. Sundaily. Modezone. NNB. Coffee. Game News. FrontStreet. GGAMEN
© 2024 shulou.com SLNews company. All rights reserved.
 12
12
 Report
Report







