

![]()

In addition to Weibo, there is also WeChat
Please pay attention
![]()
WeChat public account
Shulou




![]()
2026-03-28 Update From: SLTechnology News&Howtos shulou NAV: SLTechnology News&Howtos > Servers >
Share
Shulou(Shulou.com)05/31 Report--
Most people do not understand the knowledge points of this article "what are two similar api in Spark?", so the editor summarizes the following content, detailed content, clear steps, and has a certain reference value. I hope you can get something after reading this article. Let's take a look at this "what are two similar api in Spark" article.
There are two similar api in Spark, reduceByKey and groupByKey. The functions of the two are similar, but the underlying implementation is somewhat different, so why design it this way? Let's analyze it from the perspective of source code.
First look at the calling order of both (both use the default Partitioner, that is, defaultPartitioner)
Spark version used: spark 2.1.0
# check reduceByKey first
Step1
`
Def reduceByKey (func: (v, V) = > V): RDD [(K, V)] = self.withScope {
ReduceByKey (defaultPartitioner (self), func)
}
`
Setp2
`
Def reduceByKey (partitioner: Partitioner, func: (v, V) = > V): RDD [(K, V)] = self.withScope {
CombineByKeyWithClassTag [V] ((v: v) = > v, func, func, partitioner)
}
`
Setp3
`
Def combineByKeyWithClassTag [C] (
CreateCombiner: v = > C
MergeValue: (C, V) = > C
MergeCombiners: (C, C) = > C
Partitioner: Partitioner
MapSideCombine: Boolean = true
Serializer: Serializer = null) (implicit ct: ClassTag [C]): RDD [(K, C)] = self.withScope {
Require (mergeCombiners! = null, "mergeCombiners must be defined") / / required as of Spark 0.9.0
If (keyClass.isArray) {
If (mapSideCombine) {
Throw new SparkException ("Cannot use map-side combining with array keys.")
}
If (partitioner.isInstanceOf [HashPartitioner]) {
Throw new SparkException ("HashPartitioner cannot partition array keys.")
}
}
Val aggregator = new Aggregator [K, V, C] (
Self.context.clean (createCombiner)
Self.context.clean (mergeValue)
Self.context.clean (mergeCombiners))
If (self.partitioner = = Some (partitioner)) {
Self.mapPartitions (iter = > {
Val context = TaskContext.get ()
New InterruptibleIterator (context, aggregator.combineValuesByKey (iter, context))
}, preservesPartitioning = true)
} else {
New ShuffledRDD [K, V, C] (self, partitioner)
.setSerializer (serializer)
.setAggregator (aggregator)
.setMapSideCombine (mapSideCombine)
}
}
`
Without looking at the details of the method, we just need to know that the method combineByKeyWithClassTag is finally called. This method has two parameters. Let's focus on it.
`
Def combineByKeyWithClassTag [C] (
CreateCombiner: v = > C
MergeValue: (C, V) = > C
MergeCombiners: (C, C) = > C
Partitioner: Partitioner
MapSideCombine: Boolean = true
Serializer: Serializer = null)
`
The first is the * * partitioner** parameter, which is the partition setting of RDD. In addition to the default defaultPartitioner,Spark also provides RangePartitioner and HashPartitioner, users can also customize partitioner. Through the source code, you can find that if it is HashPartitioner, then an error will be thrown.
Then there is the * * mapSideCombine** parameter, which is the biggest difference between reduceByKey and groupByKey. It determines whether to perform a Combine operation on the node first. There will be a more specific example below.
# and then groupByKey
Step1
`
Def groupByKey (): RDD [(K, Iterable [V])] = self.withScope {
GroupByKey (defaultPartitioner (self))
}
`
Step2
`
Def groupByKey (partitioner: Partitioner): RDD [(K, Iterable [V])] = self.withScope {
/ / groupByKey shouldn't use map side combine because map side combine does not
/ / reduce the amount of data shuffled and requires all map side data be inserted
/ / into a hash table, leading to more objects in the old gen.
Val createCombiner = (v: v) = > CompactBuffer (v)
Val mergeValue = (buf: CompactBuffer [V], v: v) = > buf + = v
Val mergeCombiners = (C1: CompactBuffer [V], c2: CompactBuffer [V]) = > C1 + + = c2
Val bufs = combineByKeyWithClassTag [CompactBuffer [V]]
CreateCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
Bufs.asInstanceOf [RDD [(K, Iterable [V]
}
`
Setp3
`
Def combineByKeyWithClassTag [C] (
CreateCombiner: v = > C
MergeValue: (C, V) = > C
MergeCombiners: (C, C) = > C
Partitioner: Partitioner
MapSideCombine: Boolean = true
Serializer: Serializer = null) (implicit ct: ClassTag [C]): RDD [(K, C)] = self.withScope {
Require (mergeCombiners! = null, "mergeCombiners must be defined") / / required as of Spark 0.9.0
If (keyClass.isArray) {
If (mapSideCombine) {
Throw new SparkException ("Cannot use map-side combining with array keys.")
}
If (partitioner.isInstanceOf [HashPartitioner]) {
Throw new SparkException ("HashPartitioner cannot partition array keys.")
}
}
Val aggregator = new Aggregator [K, V, C] (
Self.context.clean (createCombiner)
Self.context.clean (mergeValue)
Self.context.clean (mergeCombiners))
If (self.partitioner = = Some (partitioner)) {
Self.mapPartitions (iter = > {
Val context = TaskContext.get ()
New InterruptibleIterator (context, aggregator.combineValuesByKey (iter, context))
}, preservesPartitioning = true)
} else {
New ShuffledRDD [K, V, C] (self, partitioner)
.setSerializer (serializer)
.setAggregator (aggregator)
.setMapSideCombine (mapSideCombine)
}
}
`
Combined with the above reduceByKey call chain, you can find that in the end, the method combineByKeyWithClassTag is actually called, but with different parameters.
The call of reduceByKey
`
CombineByKeyWithClassTag [V] ((v: v) = > v, func, func, partitioner)
`
The call of groupByKey
`
CombineByKeyWithClassTag [CompactBuffer [V]] (
CreateCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
`
It is the different ways of calling the two methods that lead to the difference between the two methods. Let's look at them separately.
The generic parameter of-reduceByKey is directly [V], while the generic parameter of groupByKey is [CompactBuffer [V]]. This directly leads to the difference between the return values of reduceByKey and groupByKey. The former is RDD [(K, V)] and the latter is RDD [(K, Iterable [V])].
-then there is mapSideCombine = false. The default for this mapSideCombine parameter is true. What is the use of this value? as mentioned above, the function of this parameter is to control whether or not to Combine on the map side. Take a look at the following specific examples.
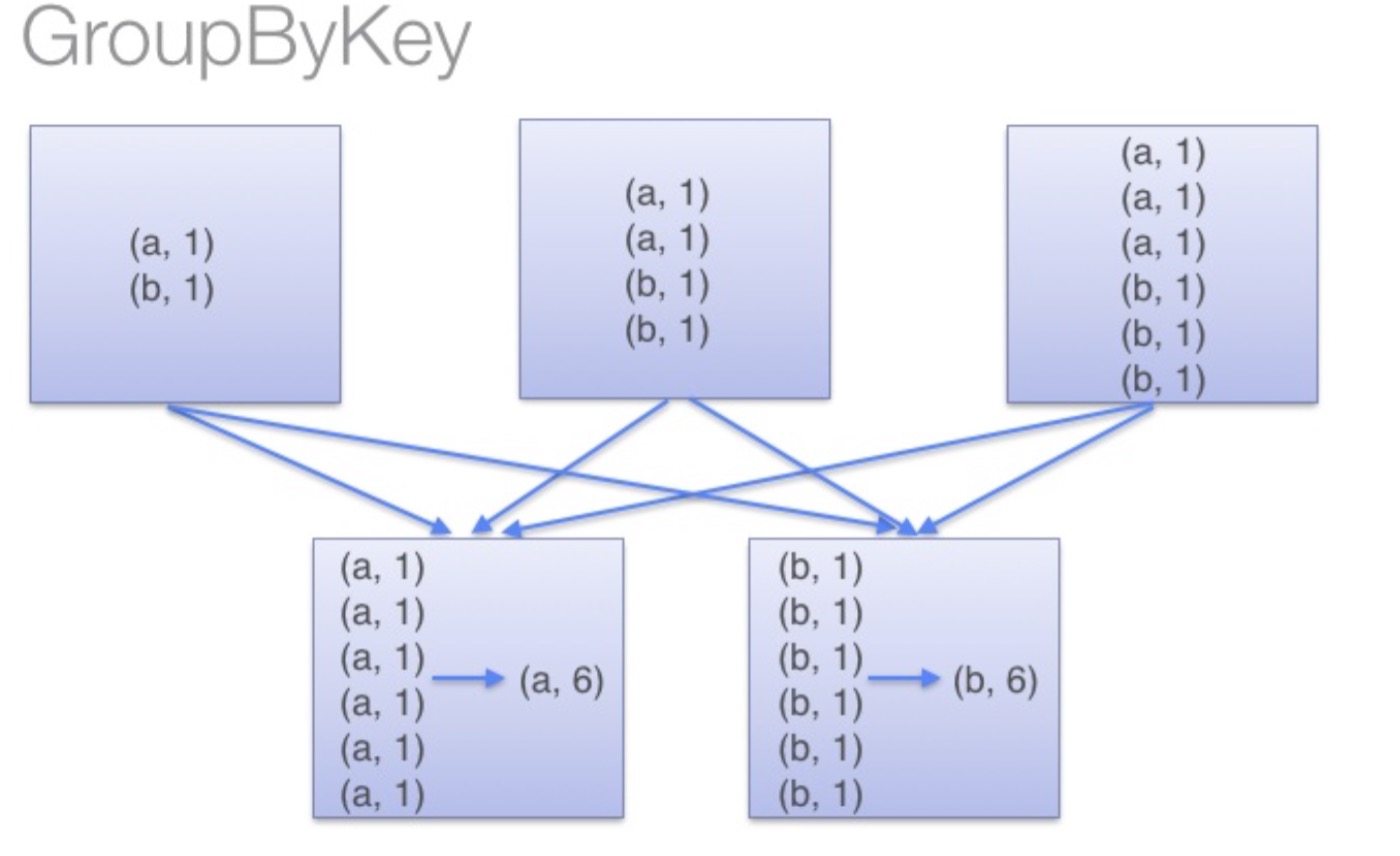
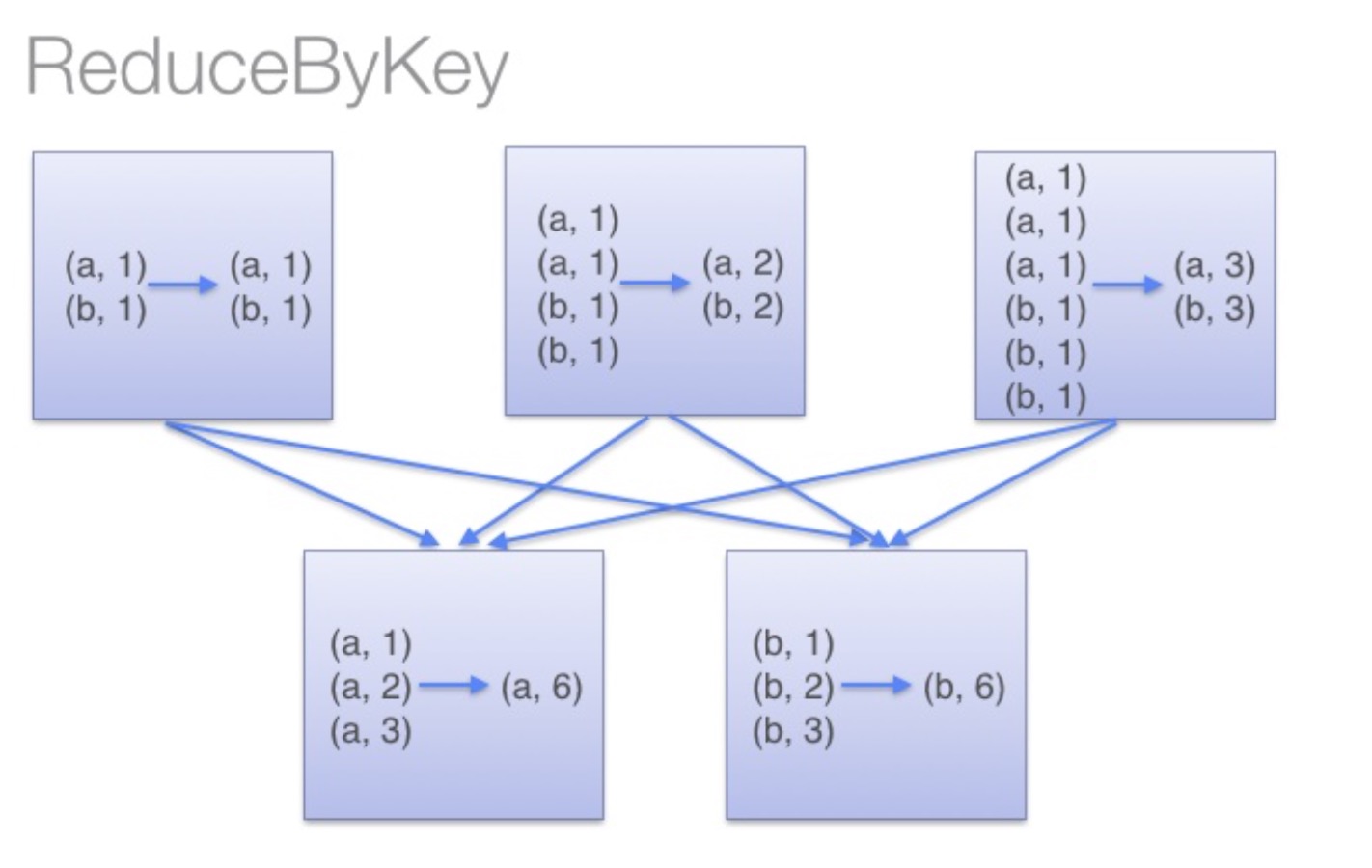
Functionally, you can find that ReduceByKey actually performs a * * merge * * operation on each node, while groupByKey does not.
From this point of view, the performance of ReduceByKey will be much better than that of groupByKey, because some of the work has already been handled on the node.
The above is about the content of this article on "what are two similar api in Spark". I believe we all have some understanding. I hope the content shared by the editor will be helpful to you. If you want to know more about the relevant knowledge, please pay attention to the industry information channel.
Welcome to subscribe "Shulou Technology Information " to get latest news, interesting things and hot topics in the IT industry, and controls the hottest and latest Internet news, technology news and IT industry trends.
Views: 0
*The comments in the above article only represent the author's personal views and do not represent the views and positions of this website. If you have more insights, please feel free to contribute and share.

The market share of Chrome browser on the desktop has exceeded 70%, and users are complaining about

The world's first 2nm mobile chip: Samsung Exynos 2600 is ready for mass production.According to a r


A US federal judge has ruled that Google can keep its Chrome browser, but it will be prohibited from

Continue with the installation of the previous hadoop.First, install zookooper1. Decompress zookoope



About us Contact us Product review car news thenatureplanet
More Form oMedia: AutoTimes. Bestcoffee. SL News. Jarebook. Coffee Hunters. Sundaily. Modezone. NNB. Coffee. Game News. FrontStreet. GGAMEN
© 2024 shulou.com SLNews company. All rights reserved.
 12
12
 Report
Report







